
In the previous pipelines, I’ve been using Python and had to install multiple pip modules. Suppose we have 5 different jobs, we would be installing the pip modules again and again for each job, which takes a while to complete. Remember, each job runs in its own pristine environment, meaning it builds a fresh Docker container and installs all the required modules before running the script we need. This repetition can slow down the pipeline significantly.
In this blog post, let’s look at how you can use GitLab Cache to speed up your jobs and avoid unnecessary reinstallations. If you are new to GitLab or CI/CD in general, I highly recommend checking out my previous GitLab introduction post below.
 Suresh Vina
Suresh Vina
The Problem With My Previous Approach
This is how my pipeline looked before. Though it worked perfectly fine, it took around 45 seconds to run each job and just over 3 minutes for the entire pipeline to run. Most of the time was spent on installing pip modules. This got me thinking, all my jobs use the exact same modules. Is there a way to cache the pip packages and pass them to the other jobs? Well, there is, by using ‘Cache’.
default:
image: python:3.10
stages:
- pre-test
- stage
- deploy
- post-check
Pre-Checks (ANTA):
stage: pre-test
before_script:
- pip install -r requirements.txt
script:
- cd tests
- python anta_tests.py
only:
- main
Pre-Checks (VLAN Validation):
stage: pre-test
before_script:
- pip install -r requirements.txt
script:
- cd tests
- ansible-playbook valid_vlan.yaml
Staging:
stage: stage
before_script:
- pip install -r requirements.txt
script:
- cd nornir
- python push_config.py
Deploy:
stage: deploy
variables:
DRY_RUN: "false"
before_script:
- pip install -r requirements.txt
script:
- cd nornir
- python push_config.py
only:
- main
Post-Checks (ANTA):
stage: post-check
before_script:
- pip install -r requirements.txt
script:
- cd tests
- python anta_tests.py
only:
- main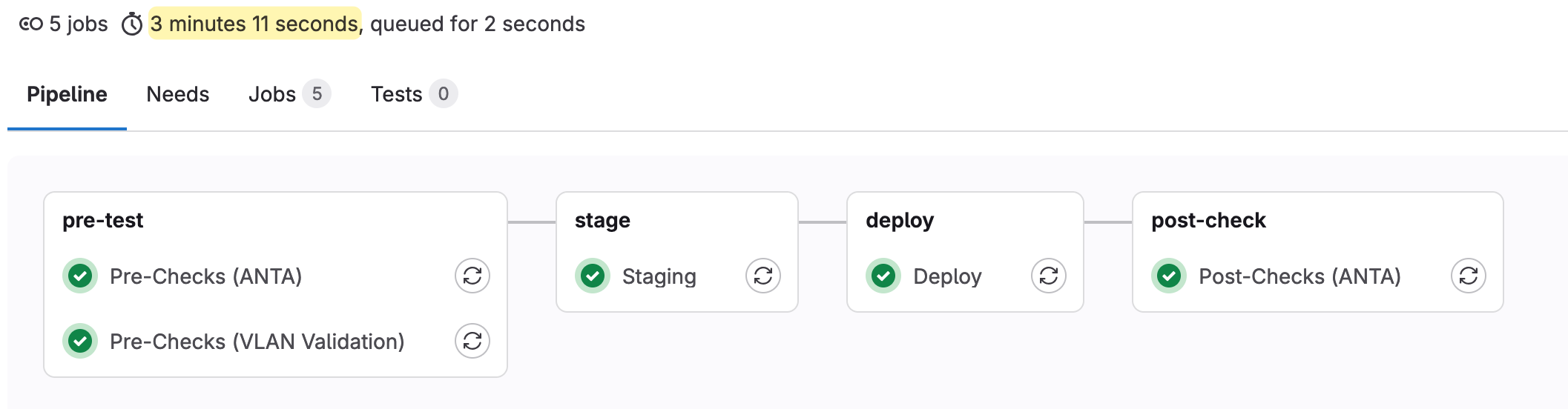
Here is the GitLab repository for this example so you can follow along. Feel free to clone the repo, explore the pipeline setup, and try it out in your environment.
GitLab Cache
GitLab Cache is a mechanism that allows you to store and reuse files across different jobs in your pipeline. It helps you avoid repetitive tasks, like downloading dependencies or building files, by caching files between jobs. When jobs use the same environment or resources, caching allows subsequent jobs to access these resources without rebuilding or reinstalling them, significantly speeding up the pipeline.
In many CI pipelines, jobs start in a clean environment, which means they must install dependencies or rebuild files every time they run. This can be time-consuming, especially if you’re repeatedly installing the same set of dependencies (like pip packages). With GitLab Cache, you can store these dependencies during the first job and reuse them in subsequent jobs.
For example, instead of installing pip packages in every job, you can cache the installed packages after the first job and reuse them for the rest of the pipeline. Here is a simple example and syntax on how to use cache.
cache:
key: my-cache
paths:
- venv/
stages:
- install
- test
Install Dependencies:
stage: install
script:
- python -m venv venv
- source venv/bin/activate
- pip install -r requirements.txt
cache:
key: my-cache
paths:
- venv/
Test:
stage: test
script:
- source venv/bin/activate
- python my_script.py
cache:
key: my-cache
paths:
- venv/- cache - Defines the cache settings, including the key (a unique identifier for the cache) and the paths (files or directories) that should be cached.
- key - Identifies the cache uniquely. Jobs with the same cache key will share the same cached files.
- paths - The files or directories that will be stored in the cache and reused in later jobs.
- Install Dependencies job - Creates the virtual environment (
venv/), installs the dependencies, and caches thevenv/directory. - Test job - Pulls the cached
venv/directory and reuses it without needing to reinstall the dependencies.
Modifying Our Pipeline
In this modified pipeline, you might have noticed that for the cache key, I’ve used ${CI_COMMIT_SHA}. This is a unique identifier that GitLab automatically generates based on the latest commit. By using ${CI_COMMIT_SHA}, I ensure that a new cache is created every time I commit. This helps avoid using outdated cache data and ensures the most up-to-date dependencies are cached.
default:
image: python:3.10
cache:
key: "venv-cache-${CI_COMMIT_SHA}"
paths:
- venv/
policy: pull
stages:
- pre-test
- stage
- deploy
- post-check
before_script:
- source venv/bin/activate
Pre-Checks (VLAN ID Validation):
stage: pre-test
before_script:
- python -m venv venv
- source venv/bin/activate
- pip install -r requirements.txt
script:
- cd tests
- ansible-playbook valid_vlan.yaml
cache:
key: "venv-cache-${CI_COMMIT_SHA}"
paths:
- venv/
policy: pull-push
Pre-Checks (ANTA):
stage: pre-test
script:
- cd tests
- python anta_tests.py
needs: ["Pre-Checks (VLAN ID Validation)"]
only:
- main
Dry-Run:
stage: stage
script:
- cd nornir
- python push_config.py
Deploy:
stage: deploy
variables:
DRY_RUN: "false"
script:
- cd nornir
- python push_config.py
only:
- main
Post-Checks (ANTA):
stage: post-check
script:
- cd tests
- python anta_tests.py
only:
- mainFor the cache policy, I’ve set the default to pull. This means the jobs will only pull the cache and won’t attempt to push or update it. However, I changed the behaviour for the first job, Pre-Checks (VLAN ID Validation), to use pull-push. The reason behind this is that I want the first job to actually create the cache and push it (i.e., save the venv directory) to GitLab. Every other job in the pipeline should only pull this cache since they don’t need to modify it. The default cache policy in GitLab is pull-push, but I’ve overridden it for the other jobs to prevent unnecessary pushing.
I also had to make a change to the pre-test stage. Initially, both Pre-Checks (VLAN ID Validation) and Pre-Checks (ANTA) were running in parallel. However, since I was using the cache from the first job, I didn’t want them to run at the same time and risk a race condition. To solve this, I made Pre-Checks (ANTA) depend on Pre-Checks (VLAN ID Validation) using the needs keyword. This way, it waits for the VLAN validation job to complete before starting.
Additionally, I created a global before_script to source the virtual environment (venv). This eliminates the need for the other jobs to even trying reinstall dependencies. They simply activate the cached venv, and that’s all they need to proceed with their tasks.
Let's Check the Run Time
After rerunning the pipeline and checking the times, the entire pipeline now took only 2 minutes, saving us a whole minute compared to the previous run. The first job, which generates the cache, took around 55 seconds.
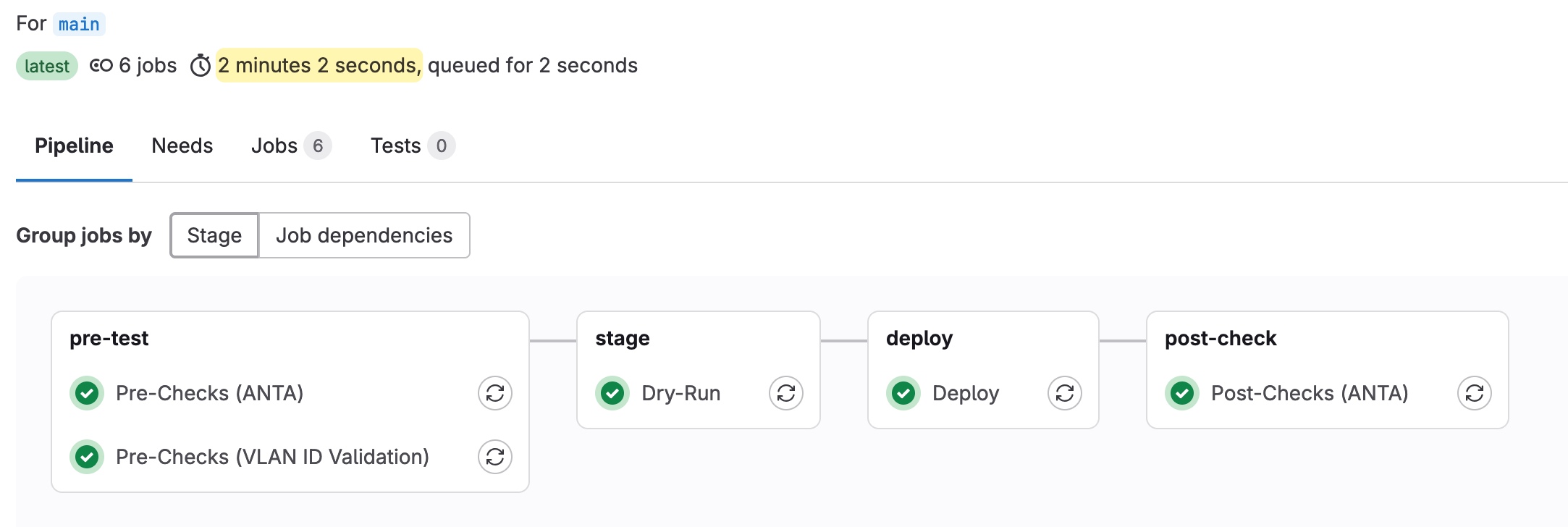
However, every subsequent job, which simply pulled the cache instead of reinstalling the pip modules, took only around 15 seconds. This is a significant improvement from the 45 seconds per job in the earlier version of the pipeline.
Closing Up
In this post, we saw how using GitLab's cache can significantly speed up your CI/CD pipeline by avoiding repetitive tasks like installing dependencies for each job. By caching the venv directory and optimizing job dependencies, we managed to cut the overall runtime by a minute.




