

Hi all, welcome to the 'Network CI/CD' blog series. To kick things off, let's ask the question, "Why do we even need a CI/CD pipeline for networks?" Instead of diving straight into technical definitions or showing you how to build a CI/CD pipeline, which might make you lose interest, we’ll focus on the reasons behind it. Why should network teams even consider implementing CI/CD?
In this post, we’ll talk about the benefits and the problems it solves, so you can see why it's worth learning. Let's get to it.
Making Network Changes - The Traditional Way
Even though I call it the “traditional way,” most of us (myself included) still make changes via the CLI. So, let’s imagine you and two colleagues are managing a campus network with 10 access switches. One of your tasks is to configure VLANs on all of them. To keep things simple, let’s assume you’re not using VTP. When a request comes in to create a new VLAN, here’s what you typically do.
- Prepare the configuration - usually just a couple of commands, one to create the VLAN and another to assign a VLAN name.
- Raise a change control ticket explaining the change.
- One of your colleagues reviews and approves the change.
- You implement the change by creating the VLAN on all 10 switches.
vlan 10
name usersIt works, right? We’ve done this thousands of times. So, what’s wrong with this approach? Well, I’m not saying it’s completely wrong, but here are some challenges.
- What happens if you accidentally skip creating the VLAN on one of the switches?
- How do you verify the changes? Do you do it manually?
- How do you ensure standards are followed, like which VLAN IDs to use, or the naming conventions like using upper case, hyphens, or underscores?
- Sure, the reviewer can reject the ticket, but then you have to create another one, which can be frustrating.
- If you need to create a new VLAN the next day, you have to repeat the steps all over again.
This process is time-consuming and prone to errors. So, how can we make it better?
Create an Automation Script
So, you’ve had enough of making manual changes and decide to automate the process. You choose Ansible and write a simple Ansible Playbook that creates VLANs on all 10 switches. Now, when a new request comes in, all you have to do is add the VLAN information to the playbook and run it. That’s it. This is definitely an improvement over the previous method. It saves time, reduces the chance of manual errors, and makes the process more consistent.
vlans:
- vlan_id: 10
name: cctv
- vlan_id: 11
name: voip---
- name: "VLAN Playbook"
hosts: switches
gather_facts: no
vars_files:
- vlans.yml
tasks:
- name: Create VLANs
arista.eos.eos_vlans:
config: "{{ vlans }}"Now, your colleagues see what you’re doing and ask for the script. They start using it as well. So, when a new request comes in, one of you picks it up, updates the playbook to include the new VLAN, runs it, and everything works fine. But some problems start to show up.
- Over time, you might make changes to the playbook or update it with additional functionality.
- Your colleagues might also update the script, adding their own tweaks and improvements.
- Now, you’re in a situation where each of you has a slightly different version of the script, and you need to constantly update each other's copies to keep everything consistent.
This gets messy quickly, so you start looking for a solution.
Add the Script to Git
The next logical step is to put the playbook into a Git repository. Now, everything is in one central place. When a new request comes in, one of you can pick up the ticket, create a feature branch, update the playbook, and run it. Once everything works as expected, you merge the feature branch back into the main branch. Even if you want to improve the script, you can just pull the latest version, update it, and push it back to the repo. This solves the problem of manually updating the script between each other. But there are still areas for improvement.
- Can we automate some manual checks, like ensuring we’re using the correct VLAN IDs? (For example, suppose you only want to use VLANs 10-100.)
- If I run the playbook locally on my machine, how do we keep track of the audit trail?
- Ideally, we want to update the code, push it to Git, and at that stage, run some automated tests before merging it.
- As soon as we merge, we need to automatically deploy the changes to our network i.e. create the VLANs.
This is where a CI/CD pipeline for network automation becomes valuable.
 Suresh Vina
Suresh Vina
CI/CD Pipeline Approach
Now, let’s look at how this could work in our scenario using a CI/CD pipeline. If I didn't mention this before, CI/CD stands for Continuous Integration and Continuous Deployment (or Delivery). So, in an ideal scenario, this is what we want to happen.
- A new request comes in to create a new VLAN.
- I pick it up and decide which VLAN to use (while ensuring that the VLAN ID falls within the 10-100 range).
- Create a new feature branch in git
- I update the script to include the new VLAN.
- Push the updated script back to Git, which should automatically trigger tests to check if the VLAN ID is correct.
- Create a merge request, someone reviews and approves it
- The tests run again and the configuration change is deployed to the network.
Here is a playbook that can run the tests to make sure the VLAN-ID falls within 10 and 100.
---
- name: "VLAN Validation Playbook"
hosts: localhost
gather_facts: no
vars_files:
- vlans.yml
tasks:
- name: Validate VLAN IDs are between 1 and 100
assert:
that:
- vlan.vlan_id >= 10
- vlan.vlan_id <= 100
loop: "{{ vlans }}"
loop_control:
loop_var: vlanGitLab CI/CD Pipeline
For this example, I’m using GitLab, where I host my files and also run the pipeline tasks. There are other CI tools available such as GitHub Actions or Drone CI but I'm familiar with GitLab and it's one of the easiest tools to learn.
A pipeline is a set of automated steps that run in sequence to achieve a specific goal, like testing or deploying code or changes. In the context of network automation, a pipeline helps automate tasks such as validating configurations and applying them to devices. Once triggered, the pipeline takes care of the steps for you, reducing manual work and ensuring consistency across your network.
Here’s a high-level look at how a simple pipeline might work. The pipeline is defined in a file .gitlab-ci.yml and runs inside a Docker container. In this pipeline, I have two stages - one for testing and one for deploying.
default:
image: python:3.10
stages:
- test
- deploy
test:
stage: test
before_script:
- pip install ansible paramiko
script:
- ansible-playbook pre_test.yml
deploy:
stage: deploy
before_script:
- pip install ansible paramiko
script:
- ansible-playbook create_vlan.yml
only:
- main- Test Stage - This is the first stage where we ensure everything is in order before deploying. The pipeline installs Ansible and Paramiko (a library used for SSH connections) and then runs a playbook called
pre_test.yml. This playbook is used to verify that the VLAN ID falls within the allowed range or check other conditions that must be met before deployment. - Deploy Stage - Once the tests pass, the pipeline moves to the deployment stage. Again, it installs the necessary tools (Ansible and Paramiko) and then runs the
create_vlan.ymlplaybook to deploy the VLAN configuration across the network. This stage only runs from the 'main' branch.
This automates both the validation and deployment processes, reducing the chances of human error and ensuring consistency across the network.
Here is an Example
Suppose a new request comes in, and I pick it up. The first thing I do is pull the latest Git repository to my local machine and create a feature branch. Then, I update the code to include the new VLAN, let’s say VLAN 12. Once I’m happy with my changes, I push this change to GitLab, but since I’m pushing via my feature branch, the main branch remains unchanged.
Here, I'm going to create VLAN-12 with the name apple-tv
➜ simple_cicd git:(main) git checkout -b vlan_12
Switched to a new branch 'vlan_12'
➜ simple_cicd git:(vlan_12) ✗ git status
On branch vlan_12
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: vlans.yml
➜ simple_cicd git:(vlan_12) ✗ git add vlans.yml
➜ simple_cicd git:(vlan_12) ✗ git commit -m "adding vlan 12"
➜ simple_cicd git:(vlan_12) git push origin vlan_12
remote:
To gitlab.com:vsurresh/simple_cicd.git
* [new branch] vlan_12 -> vlan_12
➜ simple_cicd git:(vlan_12)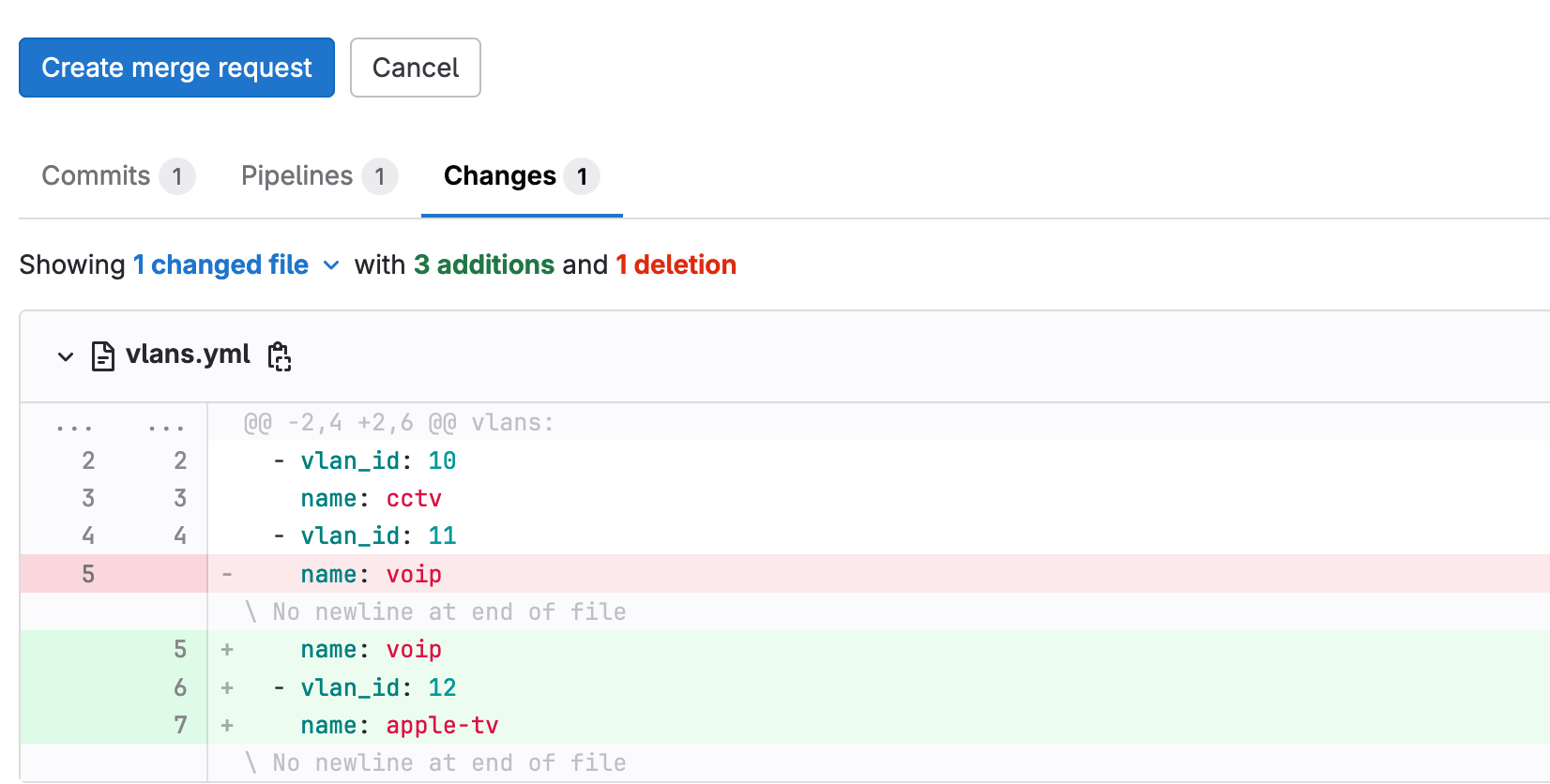
This triggers a series of events. First, the pipeline runs the ‘test’ stage, which checks if the VLAN ID falls within the allowed range of 10 to 100. I, or anyone with access to this repo, can review the changes and see whether the test passes.
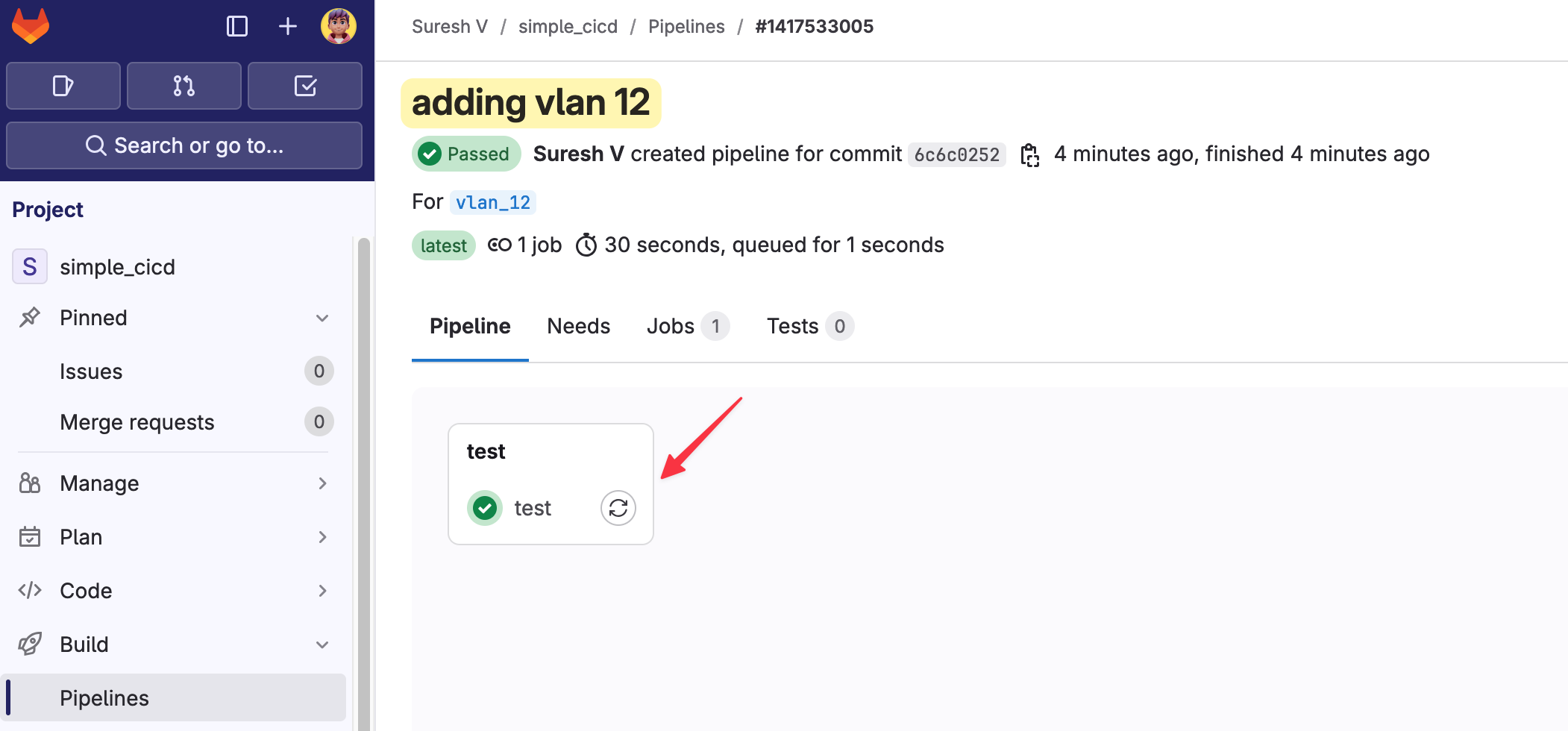
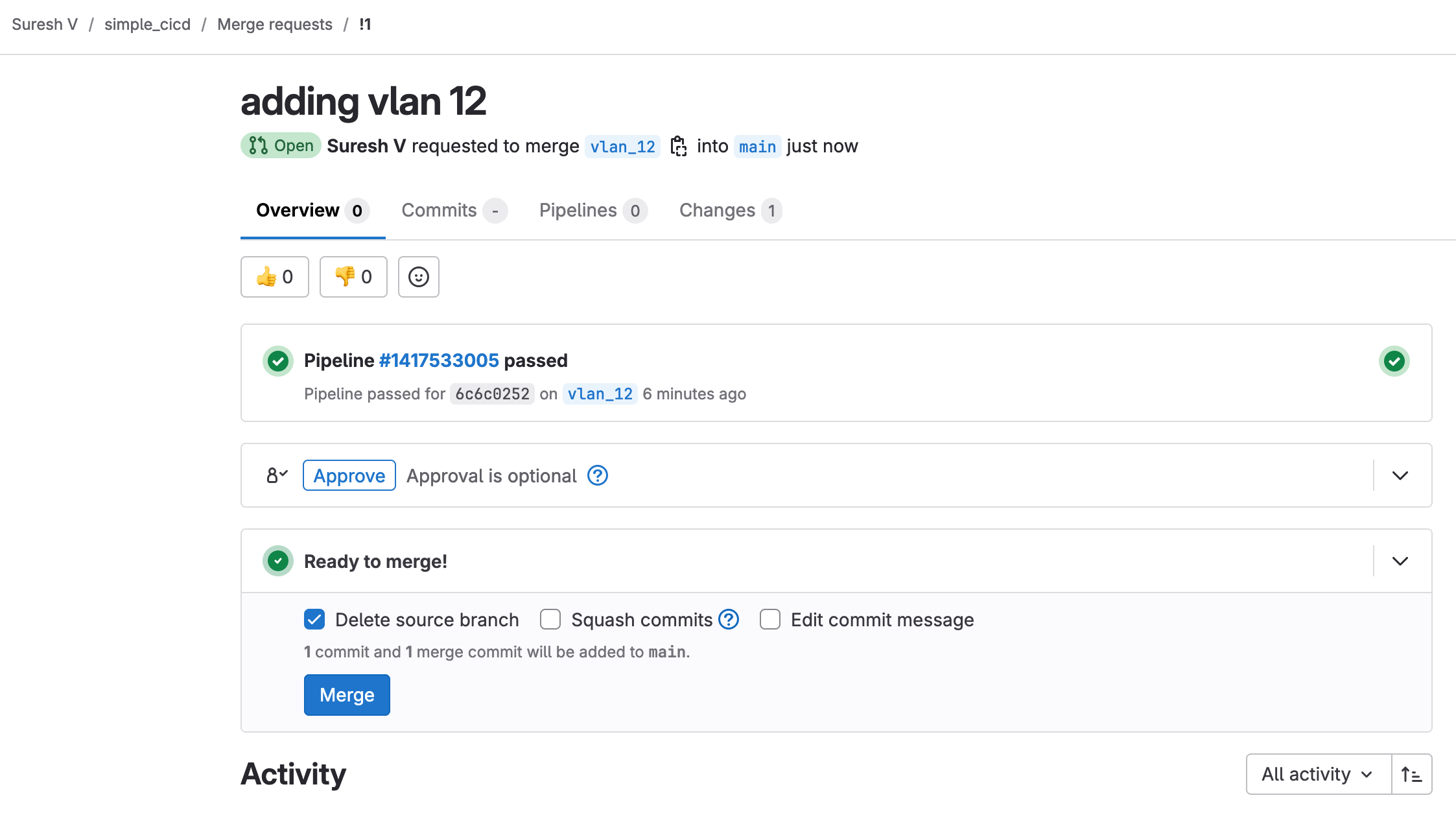
If it does, I can create a merge request, saying that I want to merge my changes into the main branch. When I create a merge request, I can ask someone to review it. Since the test has already passed, the reviewer doesn’t need to check everything manually and can approve the merge request more confidently.
As soon as the merge request is approved, it triggers the pipeline again as shown below. This time, it runs both the ‘test’ and ‘deploy’ stages. The test stage ensures that everything is still valid, and if it passes, the deployment stage pushes the VLAN configuration to the network.
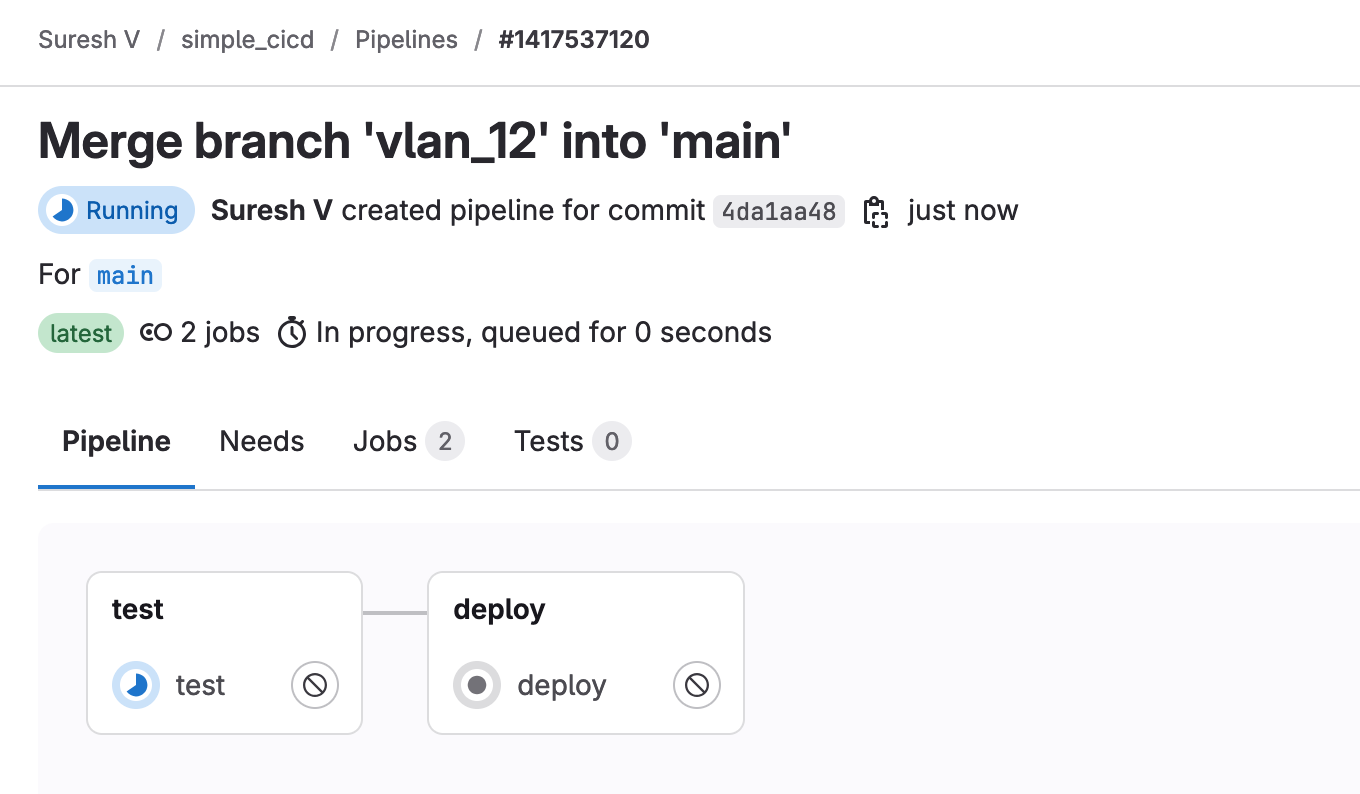

You can also view exactly what happened at each stage by opening and viewing the console output. Here in the output, you can see that the changes have been pushed to four switches.
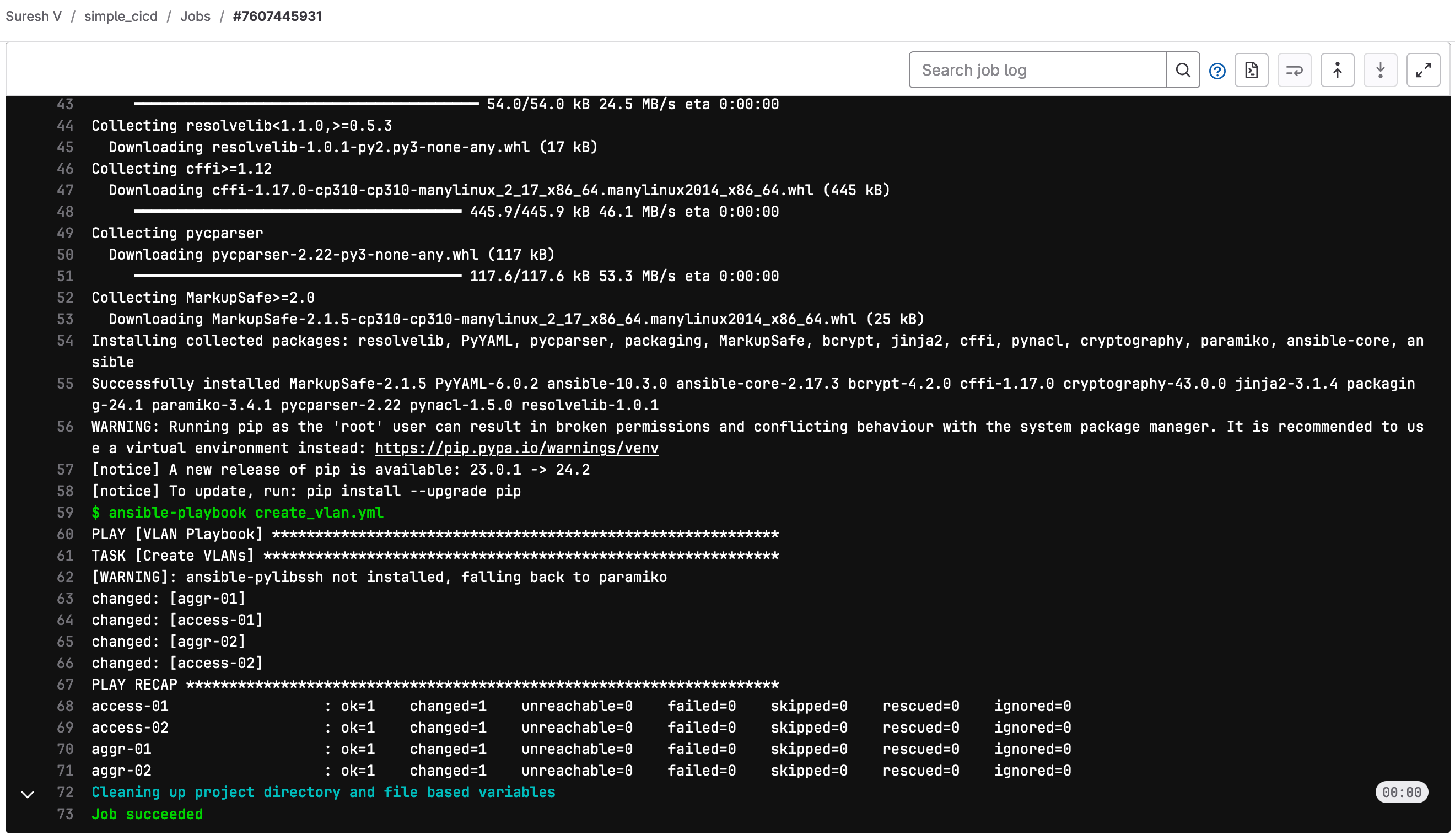
A Failing Test
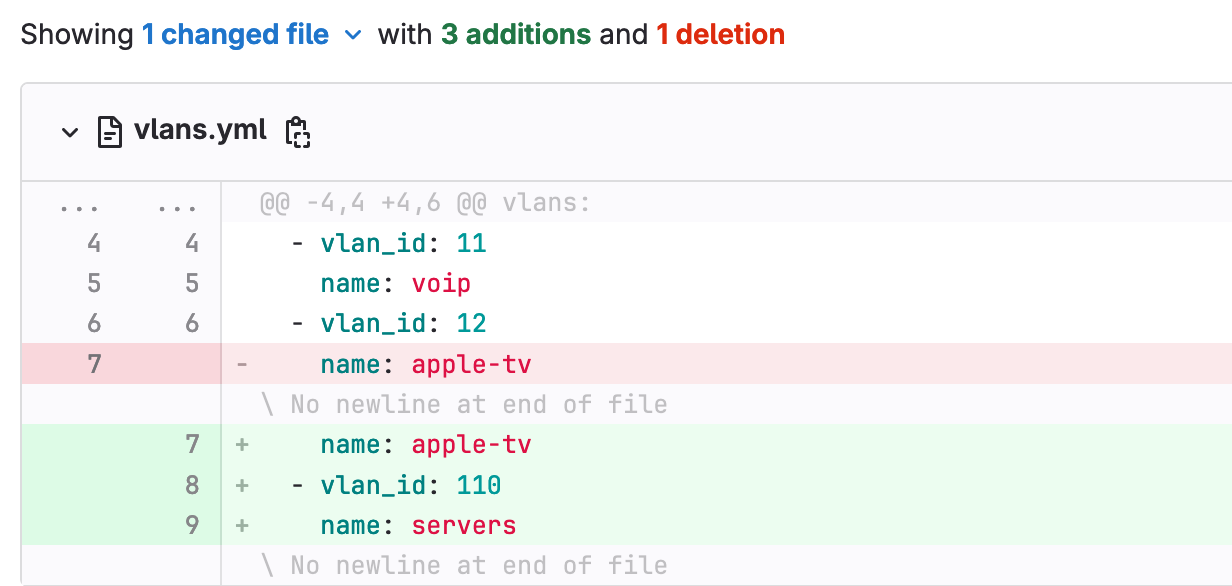
To demonstrate a failure, let’s imagine that I try to create VLAN 110, which is outside of our allowed range (10-100). When I push this change to my feature branch in GitLab, the pipeline kicks off as usual.
During the ‘test’ stage, the playbook checks whether the VLAN ID falls within the allowed range. Since VLAN 110 is invalid, this test fails.
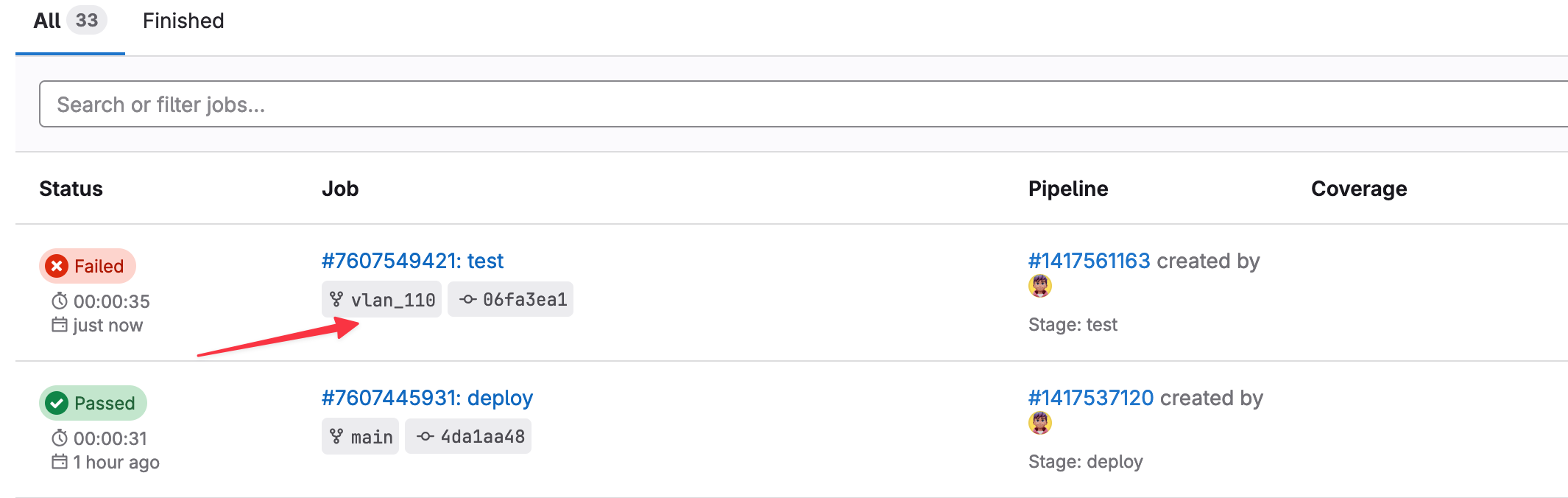
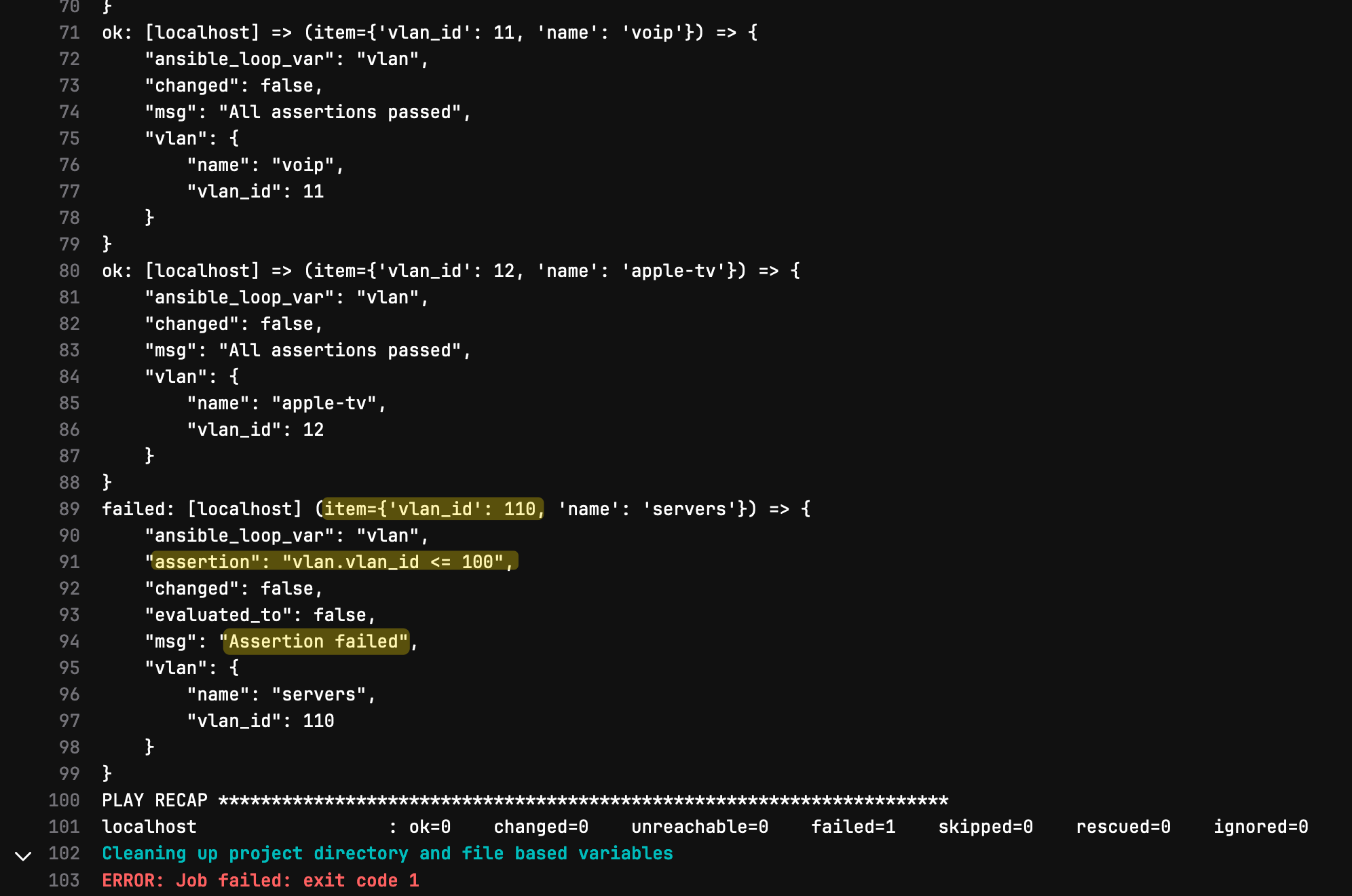
I can then go back to GitLab, review the pipeline logs, and see exactly why the test failed. This feedback loop helps catch errors early before they have a chance to impact the production network. Instead of deploying an invalid configuration, I’m alerted to the issue immediately and can fix it before proceeding.
CI/CD Definition
Now that we have covered the example and use case, let's look at the definitions. CI/CD stands for Continuous Integration and Continuous Deployment. It is a software development practice that involves automatically building, testing, and deploying changes to a codebase.
This same approach can be applied to Network Infrastructure as well. By using CI/CD principles, network engineers can automate many of the manual processes involved in managing network configurations, reducing the risk of human error and speeding up network changes. We'll explore how CI/CD works in a networking context and discuss some of the benefits it can provide.
Continuous Integration (CI) refers to the practice of frequently merging code changes into a shared repository, and then automatically building and testing the codebase. This helps to catch integration issues early in the development process. This is where I created a feature branch, made my own changes and pushed it back to the git repo.
Continuous Deployment (CD) takes this a step further by automatically deploying the tested code changes to a production environment. This allows new features and bug fixes to be released to end-users quickly and reliably.
In a networking CI/CD pipeline, the "codebase" would consist of the network configurations, scripts, and other artefacts that define the state of the network infrastructure. The CI part would involve automatically building, validating, and committing changes to a version control system. The CD part would then push those validated changes out to the live network devices.
Next Up
Next, we’ll look into GitLab and explore how you can set up a similar environment to practice and follow along. We’ll cover the basics of creating a GitLab account, setting up repositories, and configuring pipelines.
Suresh Vina





