

Welcome back to another post on local LLMs. In this post, we’ll look at setting up a fully local coding assistant inside VSCode using the Continue extension and Ollama. Let’s get started.
As always, if you find this post helpful, press the ‘clap’ button. It means a lot to me and helps me know you enjoy this type of content.
Overview
We’ve covered Ollama and Local LLMs in previous blog posts (linked below), but here’s a quick summary.
Ollama is a tool that lets you run large language models (LLMs) directly on your local machine. Local LLMs are language models that run on your computer instead of relying on cloud-based services like ChatGPT. This means you can use them without sending your data to external servers, which is great for privacy. They also work offline, so you’re not dependent on an Internet connection.
That said, it’s important to note that local models, especially on smaller setups, won’t match the speed or performance of cloud-based models like ChatGPT. These cloud models are powered by massive infrastructure, so they’re faster and often more accurate. However, the trade-off is privacy and offline access, which local LLMs provide.
In short, there’s no direct comparison, each has its strengths depending on your needs. Now, let’s see how to set up a local coding assistant in VSCode.
Action Plan
In this setup, we’ll use three main tools - Ollama, VSCode, and an extension called Continue. Continue is a VSCode extension that integrates LLMs directly into your editor, making it easier to use AI coding assistance.
We’ll also use two local models - one for general chat and another specifically for code autocomplete. The chat model will help with answering questions, explaining concepts, or brainstorming ideas, while the code-focused model will assist with writing, auto-complete, and improving your code.
Models We’ll Use
For chat, we’ll use Llama 3.2 great for answering questions and explaining concepts. For code autocomplete, we’ll use Qwen 2.5 Coder, a model specifically fine-tuned for coding tasks like writing, debugging, and improving code.
These models will run locally, ensuring your data stays private and accessible offline. Let’s move on to setting them up.
codestral, which Ollama recommends. However, when I tested it with my 16GB of RAM, it was quite slow, so I opted for a smaller model. Feel free to choose a different one if it better suits your setup.Setting Up Olama and Installing the Models
Installing Ollama is straightforward, just download the installer and run it on your machine. I’m testing this on my M3 MacBook Pro with 18GB of RAM. If you’re new to Ollama, I covered it in a previous introductory post, so feel free to check that out for more details.
Once Ollama is installed, you’ll need to pull the two models we’ll be using. Run the following commands in your terminal.
ollama pull llama3
ollama pull qwen2.5-coder Each model is around 4GB (if I remember correctly), so it might take some time to download them depending on your internet speed. Once the download is complete, you can verify the installation by running ollama list
➜ ~ ollama list
NAME ID SIZE MODIFIED
qwen2.5-coder:latest 2b0496514337 4.7 GB 2 days ago
llama3.2:latest a80c4f17acd5 2.0 GB 5 days agoYou should see both llama3 and qwen2.5-coder listed. With the models ready, let’s move on to setting up the Continue extension in VSCode.
VSCode and Continue Setup
To set up the Continue extension, open VSCode and install the extension called Continue.

Once installed, open the extension from the left-side menu and click on the cog wheel (settings icon). Here, you’ll need to update the config file to reference the models we installed earlier.
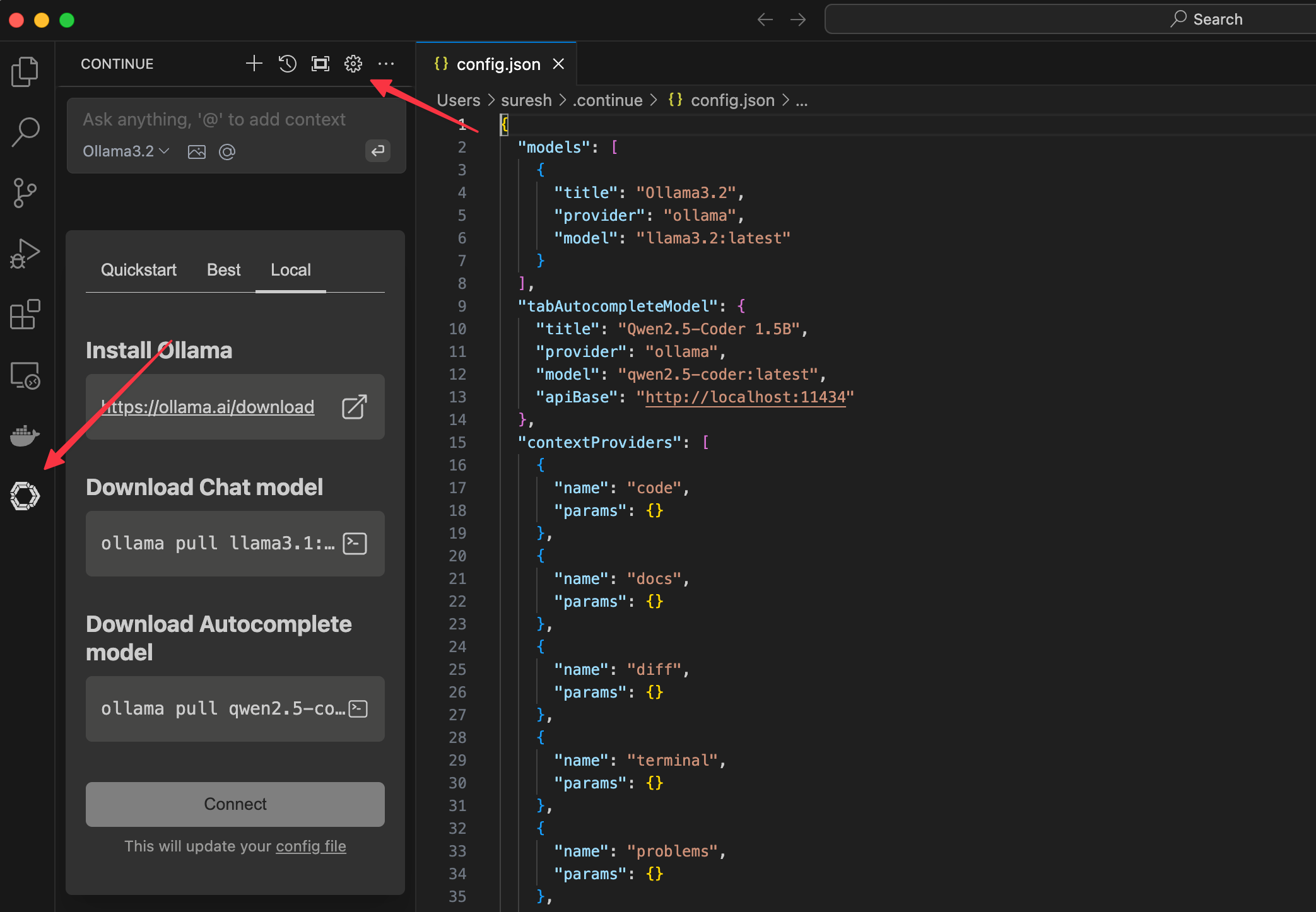
Under models, add llama3 for general chat, and for tabAutocompleteModel, add qwen2.5-coder:latest. Here’s a snippet you can copy and paste directly into your config file.
{
"models": [
{
"title": "Ollama3.2",
"provider": "ollama",
"model": "llama3.2:latest"
}
],
"tabAutocompleteModel": {
"title": "Qwen2.5-Coder 1.5B",
"provider": "ollama",
"model": "qwen2.5-coder:latest",
"apiBase": "http://localhost:11434"
}
}Testing and Verification
Let’s start by testing the chat function. Remember, we’re not expecting this local model to perform at the level of ChatGPT or Claude. Instead, we’re exploring how it can assist with small, practical coding tasks.
For this test, I have a simple Napalm script where I’ve hardcoded my password. I’ll ask the model to modify the script so that it prompts the user for the password instead. I’ll also request some general improvements to the script.
For tab autocomplete, I wanted to test if the model could predict my intent when I started typing aggr_02. Specifically, I wanted to see if it could understand that I was trying to create a second device and complete the task for me. Well, it predicted correctly, and I’m genuinely impressed.
Closing Up
I’ve only spent a few days with this setup, so I can’t draw any firm conclusions yet. However, I’ll update this post once I’ve spent more time using it. So far, though, it’s going very well.




